

Интернет-рекламодателям не нужен полный список сайтов, к которым мы получаем доступ, им достаточно 50–150 любимых веб-страниц.
В недавно опубликованном исследовании, проведенном тремя сотрудниками Mozilla, была изучена конфиденциальность, связанная с историей просмотра.
Их результаты показывают, что большинство пользователей имеют несколько уникальных веб-страниц, которые они просматривают регулярно, и эта информация позволяет онлайн-рекламодателям создавать точные профили.
Эти профили затем можно использовать для отслеживания и повторной идентификации пользователей в различных наборах пользовательских данных, которые содержат даже небольшие образцы истории просмотров пользователя.
По сути, это исследование развеивает онлайн-миф о том, что история просмотров, даже анонимная, бесполезна для онлайн-рекламодателей. В действительности исследование показывает, что даже небольшой список из 50–150 любимых и наиболее часто используемых доменов может позволить рекламодателям создать уникальный профиль отслеживания.
Исследование 2012 года
Исследовательский документ Mozilla называется "Replication: Why We Still Can't Browse in Peace: On the Uniqueness and Reidentifiability of Web Browsing Histories" [PDF].
Документ был представлен ранее в этом месяце на конференции по безопасности USENIX и является продолжением другого академического исследования, опубликованного в 2012 году [PDF].
Это исследование было одним из крупнейших проектов по анализу конфиденциальности пользователей и в то же время масштабным мероприятием для исследовательской группы, которая занималась сбором данных истории браузеров от более чем 380000 пользователей Интернета.
В период с января 2009 года по май 2011 года исследователи просили пользователей зайти на тестовый сайт, где они использовали специальный CSS код, чтобы определить, какие веб-сайты из предварительно составленного списка из 6000 доменов посетили пользователи ранее.

Исследование 2012 года показало, что 97% пользователей, заходивших на этот тестовый сайт, имели уникальный список сайтов в своей истории просмотров, что сделало историю браузера надежным вектором цифровых отпечатков.
Кроме того, когда пользователей снова попросили зайти на тестовый сайт, исследователи заявили, что они смогли повторно идентифицировать пользователей на основе их профилей истории просмотров с первого посещения.
Исследование Mozilla 2020
В прошлом году исследователи Mozilla захотели проверить, является ли история просмотров по-прежнему действительным вектором цифровых отпечатков, и актуально ли исследование 2012 года.
Новый эксперимент длился с 16 июля по 13 августа 2019 года. Исследователи Mozilla заявили, что более 52 000 пользователей согласились принять участие и согласились предоставить анонимные данные о просмотре.
Однако на этот раз, поскольку данные были собраны из самого Firefox, а не через веб-страницу, выполняющую длительный тест CSS, данные были намного более точными и надежными. Кроме того, данные, собранные исследователями Mozilla, также относятся к тому же типу данных, которые современные компании онлайн-аналитики также собирают о пользователях - через партнерские отношения, мобильные приложения, онлайн-рекламу или другие механизмы.

Как и раньше, сбор данных проходил в два этапа, в течение двух недель, когда пользователи делились историей просмотров в первую неделю, а затем снова во вторую, чтобы исследователи Mozilla могли проверить, смогут ли они повторно идентифицировать пользователей.
В общей сложности команда Mozilla заявила, что собрала данные о 35 миллионах посещений веб-сайтов на 660 000 уникальных доменов. И наличие доступа к более качественным данным сразу же отразилось в результатах исследования.
Mozilla заявила, что 99% историй браузера, которые они собрали для исследования, были уникальными.

Эта уникальность позволила исследователям Mozilla с легкостью повторно идентифицировать пользователей в течение второй недели исследования.
Точность также была выше, чем в исследовании 2012 года, при этом Mozilla заявила, что коэффициент повторной идентификации для наборов данных, содержащих только 50 доменов составил около 50% . Коэффициент повторной идентификации вырос до более чем 80%, когда исследователи Mozilla расширили набор данных истории просмотров до 150 доменов.
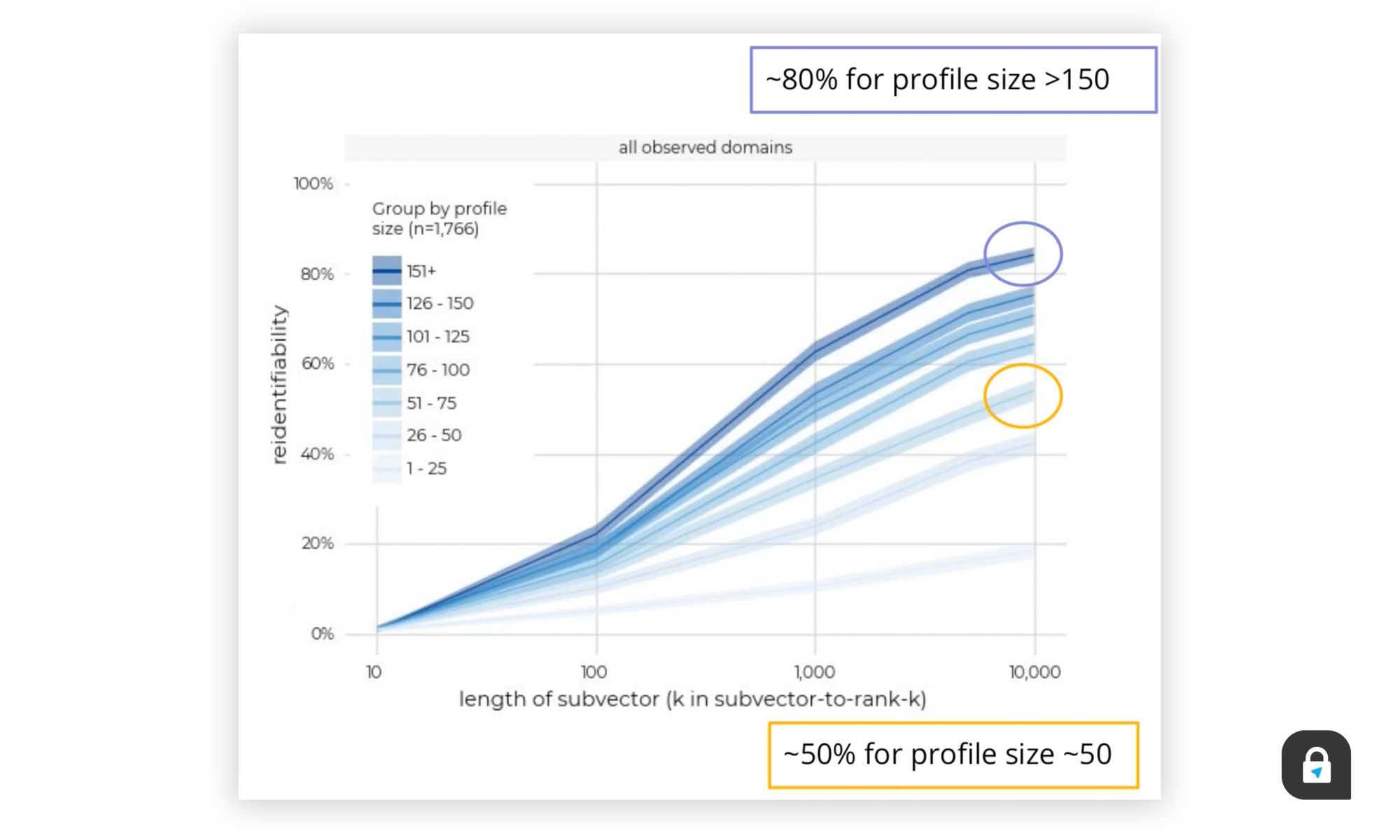
Этот последний вывод предполагает, что аналитическим фирмам и онлайн-рекламодателям не нужны огромные списки данных истории просмотров для отслеживания пользователей, и что особенности просмотра каждого пользователя и их любимые сайты в конечном итоге выдают их, даже если данные анонимны.
Видео презентации команды Mozilla доступно здесь:
Подписывайся на Эксплойт в Telegram, чтобы всегда оставаться на страже своей безопасности и анонимности в интернете.
Join the conversation.